
The platform for enterprise AI.
Same AI utility as OpenAI and Anthropic delivered faster, at lower cost. Switch in one line of code.




It takes one line of code to cut your AI cost in half.
What’s hidden inside the token?
Most AI platforms bundle model usage with cloud overhead, infrastructure margins, and licensing costs. Radium strips the token down to what actually matters, so you pay for intelligence, not inefficiency.

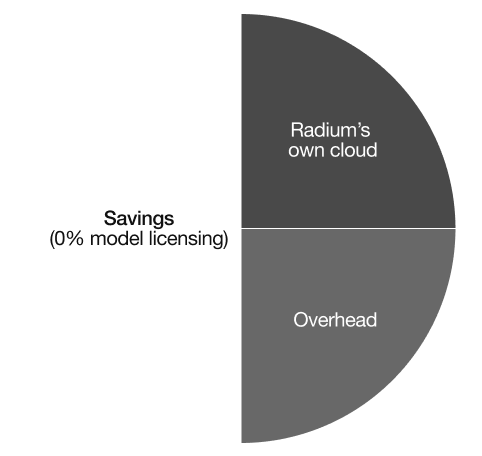
A practical alternative to default providers.
Enterprise Grade



Generative AI has quietly become expensive, fragile, and hard to control.
Costs compound faster
than usage.
Generic cloud infrastructure wasn’t built for inference-heavy workloads. As AI usage grows, inference costs scale disproportionately, making it harder to forecast spend or justify ROI.
Inference becomes efficient and predictable as usage increases.
Switching feels risky
so teams stay locked in.
Even when costs rise and performance suffers, changing infrastructure feels disruptive. Teams delay decisions because the perceived risk outweighs the short-term pain.
A one line code change to test and migrate without re-architecting.
Power and performance for AI at scale.
Radium delivers materially faster inference and lower cost than traditional cloud infrastructure.
Consistent performance under real production conditions.
Built for production AI inside enterprises
Radium is designed for teams running AI systems where performance, cost, and risk are owned.
Built to support enterprise compliance requirements across data handling, access control, auditability, and operational boundaries
Inference runs on isolated infrastructure with explicit execution boundaries.
Cost and performance scale linearly with usage, not unpredictably with demand.
No shared endpoints or opaque multi-tenant layers by default.
Designed to integrate with enterprise security, access control, and compliance workflows.
Powering real-time AI systems in live, high-stakes environments.
Modern AI is running on infrastructure that wasn’t designed for it.
Frontier model providers focus on building models. Hyperscalers focus on general-purpose cloud. Neither was built to efficiently deliver inference at production scale.
Radium exists to close that gap.

Radium is used by teams shipping AI into real-world systems.

Square’s R&D team used Radium to prototype early (pre-Gen AI) text-to-video and text-to-speech applications.

EQTY Lab used Radium to train a state-of-the-art climate model that was presented at COP28, the United Nations climate change conference.

Realbotix uses Radium to power low-latency, real-time AI interactions on its humanoid robotics platform. Radium enables responsive inference at the speed required for live human–AI interaction.

A leader in generative AI for law, Alexi used Radium to train domain-specific retrieval models. Alexi’s advanced AI platform generates legal memos, arguments, and answers to general litigation queries.
Run your AI applications 2× faster at a fraction of the cost.
